
ネット広告配信システム、いわゆるアドテク(アド・テクノロジー)の新規開発において担当したアーキテクチャ設計および開発の事例を紹介します。アドテクの技術は広範に及びますが、その中でもリアルタイム入札技術「RTB」と「DSP」に関わる狭いシステムを対象としました。
システムで実現したこと
- 1日数億件のリクエストを安定して捌く分散アーキテクチャの実現(可用性の確保)
- 1リクエスト当たり1msで処理する実装と通信方式の確立(応答速度の担保)
- 分散とモノシリックの両方に対応できるアプリケーションの実現(リソースの活用)
- 処理状況とリソース状況の可視化(計画・保守性の向上)
1. なぜ高速なレスポンスが必要なのか
Googleに代表されるネット広告ですが、ユーザがWebページにアクセスし広告枠が出現してから広告原稿が表示される0.1秒程度のかなり短い時間内で「買い付け判断」と「入札」を行っています。複数の入札者(出稿者:DSPシステム)がライバルとして存在し、最も高い値段を付けたDSPが1つ広告を出す事ができます。
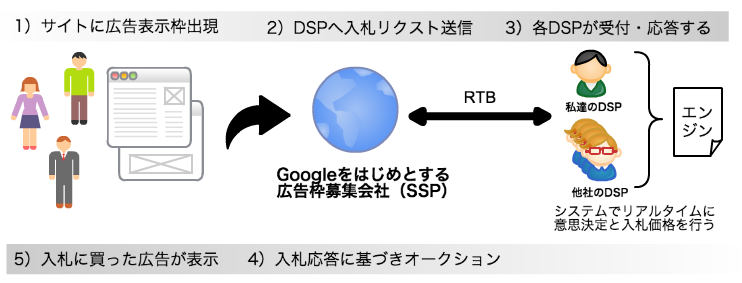
大事なポイントは2点。
高レイテンシー
入札に間に合わなければ、良い「買い付け判断」ができたとしても全てが無駄になります。 入札を含めて0.1秒なので、レイテンシなども考えると実際に使える時間は0.05秒(50ms)だと業界的には言われています。リアルタイム処理
出稿を依頼する人は限られた予算で最大限の効果を得たいので、費用対効果を考えてリアルタイムに処理行わないといけません。1日に数億件を超えるリクエストに対して50ms以内に答えを出して回答が必要になります。
2. システムに求められること
システムには良い「買い付け判断」ができるエンジンを実現することです。全ての処理を終えるのが50ms以下となる必要があり、エンジンにリクエストデータを渡す前処理・後処理に掛かる時間を差し引いて、実際にエンジンの処理時間の目標値としてあげたのは25msとなりました。 さらに、1日数億件を超えるリクエストを遅延なく並行して処理すべく、複数のサーバに処理を分散するアーキテクチャを採用する必要があります。
3. アーキテクチャ設計で考慮した事と戦略
戦略
- 分散したエンジンとデータを通信する際に通信速度のロスを最小にする
(通信データのシリアライズは必要で高速性能と安定性を重視) - エンジンを分散する際に高価なLBを間に入れるとコストと性能で頭打ちになる可能性があるので避ける
- ソフトウェアロードバランサはL7まで対応していて実績が豊富なものを利用する
- 呼び出し元のJavaアプリケーションからの利用を容易にするため、JARファイルに固めたライブラリとして提供する
プロトタイプ
通信方式を決めるにあたって、有力な候補を机上で3つ選定し、実機で計測しました。
- MessagePackRPC
- Thrift
- ZeroMQ
一般的なリアルタイムに処理を捌く通信方式として、「Message-Driven Bean + JMS」や「WebSocket」などがありますが、処理を含めて25msという要件とリクエスト量を考えるとパンクしたり、ブローカードキューが入るとリバランス時の性能の話や、そもそも通信速度が1桁以上落ちてしまい速度性能達成ができない事が考えられ、最初から対象外としました。
シリアライザーはProtocol BuffersMessagePackやJsonなどで最も速いものを選定し、それほど速度が変わらなければ保守性を考慮して選択しました。速度選定の時に役立つ情報が下記GitHub Pageです。Javaで利用できるシリアライザーについてシリアライズ・デシリアイズそれぞれで速度値が公開されていますのでとても参考になりました。 https://github.com/eishay/jvm-serializers/wiki
fastJsonは処理速度が速くデータの取り扱いもしやすいためプロトタイプで簡易に利用しやすく、また実システムの候補の一つとしていました。最終的にはシリアライザーはProtoStuffを選択し、他のシリアライザーはインタフェースとして任意のものに取り替える事ができるようにしました。
通信方式の決定
3つの通信方式の候補を実機で測定、またその他の特徴を比較したところ、圧倒的に処理速度に優れている上にドキュメント・実績・ナレッジも多いことから、ブローカレスキューなZeroMQを採用する事に決めました。さらに、実運用にのせるまでZeroMQのContextの使い回しを始めとしたチューニングと試験を繰り返し、安定した通信を実現させました。
参考までにZeroMQの実機での測定結果は、1000回通信を連続して行ったところ、1リクエスト当たり数百nanosec(1000nanosec = 1ms, 1000ms = 1秒)で処理ができました
ZeroMQを使う上で2つのハマりポイントがありましたので、もしこれから使おうと思っている方がいれば何かの参考にして頂ければと思います。
ZeroMQについて
ZeroMQについては下記情報を参考にしてください。
ZeroMQハマリポイント1
JavaからZeroMQを利用するには主に2つのライブラリが存在します。1つ目はPureJavaで書かれたjeromqで、2つ目がOSにインストールしてJavaアプリケーションから外部ライブラリとして利用するjzmqです。
当初はjeromqで利用していたのですが、試験で数千万件のリクエストを連続して処理していると、consumer側でpoolして利用していたcontextがなぜか壊れて利用できなくなる減少が発生しました。壊れたらcontextを作り直すのにもコストがかかり、ある一定数のリクエストを処理後に毎回作り直すのも本質的な解決法ではないので、ソースコードを奥深くまで追って対応方法を探るなど苦心しました。
- 解決方法
jeromqのcontextが壊れる問題の比較検証としてjzmqを利用した所、なんとcontextが壊れる事はなくとても安定して動作しました! 最終的に乗り換えを検討しjzmqに移行し現在も安定してプロダクション環境で動き続けています。
これは、当社が開発・検証していた2014年時点の話で現在のjeromqのmasterでも同じとは限らないので一度検証される事をお勧めします。 - 参照情報
ZeroMQハマリポイント2
次にJVMのメモリリークについてです。このシステムは数十msの世界で大量の処理を捌いています。JVMではFullGCが発生した際に全ての処理が止まってしまい("Stop-The-World" と言われる現象です)、利用メモリが多い程、その影響が大きくなります。同じく試験中にメモリリークによって想定以上のメモリが使用され、FullGCが頻発する現象が発生しました。このシステムはディスクアクセスが走ったら致命的に速度の代償となり、結果的に入札に間に合わなくなることを避けるため、ディスクアクセスが発生しないようオンメモリでデータを扱う設計であり、メモリも潤沢に利用しています。FullGCが発生すると、これが裏目にでて長時間、処理が止まってしまうことになります。 こちらもZeroMQのソースコードの奥底、細部まで調査し、発生箇所は特定したのですが利用方法も間違っていない事も確信し、最終的には実行環境のJVMのバージョンが影響してることを突き止めました。
- 解決方法
JVM実行環境をJava6からJava7に移行した事でメモリリークが発生がぴたりと止まりました。 - 参考情報
こちらも参考までの資料となりますが、オンメモリとディスクアクセスとネットワークの差です。 カナダとオランダ間でネットワーク通信をしただけでレイテンシとして150msもかかってしまう事がわかります。
Latency numbers every programmer should know
L1 cache reference ......................... 0.5 ns
Branch mispredict ............................ 5 ns
L2 cache reference ........................... 7 ns
Mutex lock/unlock ........................... 25 ns
Main memory reference ...................... 100 ns
Compress 1K bytes with Zippy ............. 3,000 ns = 3 µs
Send 2K bytes over 1 Gbps network ....... 20,000 ns = 20 µs
SSD random read ........................ 150,000 ns = 150 µs
Read 1 MB sequentially from memory ..... 250,000 ns = 250 µs
Round trip within same datacenter ...... 500,000 ns = 0.5 ms
Read 1 MB sequentially from SSD* ..... 1,000,000 ns = 1 ms
Disk seek ........................... 10,000,000 ns = 10 ms
Read 1 MB sequentially from disk .... 20,000,000 ns = 20 ms
Send packet CA->Netherlands->CA .... 150,000,000 ns = 150 ms
エンジンへの分散と死活監視
使っているミドルウェアやライブラリです。

死活監視
アドネットワークから日に数億件のリクエストが複数台のWebアプリケーションサーバーに届きます。そのWebサーバーからHaproxyを経由して複数台で構成されているエンジンサーバーへリクエストが流れます。HaproxyはL7で死活監視が可能ですので、スタンドアローンのJavaアプリケーションとして起動がステータスやメトリクス情報を返せるように、jolokiaというライブラリを使いました。L7の死活監視プロトコルとしてHTTPを利用します。Apacheなどでよく使われているリクエストを全て処理し終わってからgraceful shutdownを行うことにより、リクエスト処理に取りこぼしをせず、Haproxyから切り離せる仕組みを実現しました。シャットダウンやサスペンドなどの操作はjolokiaのjmx機能を使い可用性と保守性を高めました。
メトリクスを取得する仕組みについては後述します。
エンジンへの分散
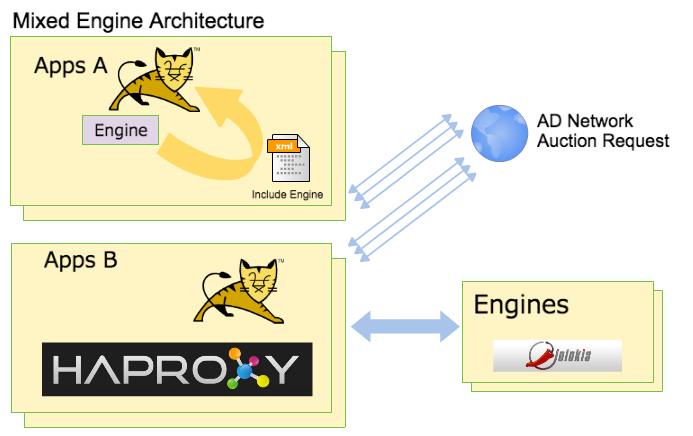 エンジンを内包・分散どちらでも使えるライブラリにしました。これは今でいうモノシリックなアプリケーションとマイクロサービスという考え方に似ています。
エンジンを内包・分散どちらでも使えるライブラリにしました。これは今でいうモノシリックなアプリケーションとマイクロサービスという考え方に似ています。
メリットとデメリットそれぞれがあるので把握した上で切り替えます。
広告枠の買い付け判断は条件により最適化したいので、分散エンジンは複数アルゴリズムを使い分け利用するエンジンを決めます。本来ならエンジンは分散しなくてもWebアプリケーション内の一つの処理とすれば、ネットワーク遅延もなく死活監視も行わずに済みますが、それに伴う問題も発生しえます。
モノシリックな構成のエンジン
- メリット
- エンジン部分の死活監視を行わなくてもよい
- サーバーを1台にまとめられるのでコスト削減を見込める
- サーバー間のデータ遅延やデータ変換ロスがない
- デメリット
- ぞれぞれのコンポーネントのリリースタイミングの調整が必要になる
- 必要なマシンリソース(CPU、メモリ)が高くなる
- 場合によってはメモリなどマシンリソース限界の関係で拡張ができなかったり難しくなる事が想定される
分散構成のエンジン
- メリット
- 負荷分散されているのでリクエスト量の変動に対して調整がしやすい
- リソースを最大化する為のパフォーマンスチューニングがしやすい
- リソースを占有できる
- デメリット
- 通信コストが余分に発生する
- サーバー台数が増えた場合にサーバー維持コストが増える
- 運用コストが増える場合がある
(逆にモノシリックな場合も運用で考慮すべき点はあるので一概に比較はできない)
分散方式の選択
現時点では全てのエンジンを分散構成で動作させており、1ms以内で処理し返却できているので通信コストが余分に発生する分を補って余りある結果を出しています。細部の実装方法に関してはここでは割愛します。
メトリクス
分散エンジンを動かしていると日々知りたい事が色々とでてきます。
- 今どれくらいリクエストを捌いているか
- 処理時間はどれくらいかかっているのか
- JVMのheapメモリの使用状況はどれくらいか
- 日々のピークや負荷状況
- etc
こういう情報をリアルタイムに把握できるようにJMX経由で利用できるMBeanサーバモニタリングツール「komuso」を使いました。komusoでcsvサポートをできるようにカスタマイズして利用しています。csvに対応したkomusoはforkしてatwareのGitHubで公開しています。
https://github.com/atware/komuso
komuso経由でとったメトリクスデータはElasticsearchに流し込んでKibanaで確認したり、リソース監視ツールのCactiの入力ファイルとして利用しました。
今回触れなかった事
1ms以内で実現する為の実装上の工夫について。
一度のディスクアクセスが入るだけで処理速度に大きく影響しますので、オンメモリ処理を前提としてデータ処理やアルゴリズムの最適化を行いました。このトピックだけで今回の事例と同じくらいのボリューになりそうですので、また機会を作ってご紹介できれば思います。
最後に
今回の事例のポイントとして
- 億を超える大量リクエストの捌き方
- 高速にリクエストを処理して返却する方式
- 分散処理の状況を把握する為の仕組み
を中心にご紹介しました。弊社では今回の事例以外にもビックデータを扱ったり非機能要件レベルが高いプロジェクトに携わっておりますので、実現可能性の参考としてください。