
2年ほど前に大量のストリームデータを処理する記事を書きました。
トラフィックはGbpsレベルの量が流れてきますので、実運用においては効率的な処理であることが、コストの大きな削減に繋がります。
この記事では、そんな環境のパフォーマンスの課題に処理の最適化チューニングでどう取り組んだかを紹介します。
パフォーマンス・最適化チューニングをする前に
進め方の方針を立てる
今回はms単位で処理の効率化に取り組む必要がありました。 パフォーマンスチューニングの際に、よく言われている事に「推測するな、計測せよ」というフレーズがあります。これは、「Rob Pike's 5 Rules of Programming」で語られています。 感覚的にあたりをつけても実際のボトルネックが違うところにあるという事は多々あります。感覚でチューニングを実施するのではなく、処理に時間がかかっている部分が全体の大部分を占めている事がわかっていない限りは計測することを優先しようという意味合いです。
このフレーズのコンセプトは重要な考えだと捉えています。限りある時間を有効に使って作業効率や方式変更にまで視野に入れて取り組む場合に、影響することは順序立てて着手する事が結果的にいい成果に繋がることを何度も体験したことがあるからです。
そこで、まず最初に計測する事がいかに重要かをチーム内で認識合わせをして、どこにボトルネックがあってどれくらい処理時間がかかっているかを把握しながら、改善に取り取り組むということを計画しました。
計測ツールの紹介
今回チューニング対象となっているシステムはJavaで実装されています。計測には様々な方法・ツールが存在しますが、Java周りのエコシステムの魅力のひとつとしてJVMのプロファイリング環境と機能が整っていることがあります。このおかげで、計測・調査作業はとても捗りました。
利用を検討した計測ツールをご紹介します。
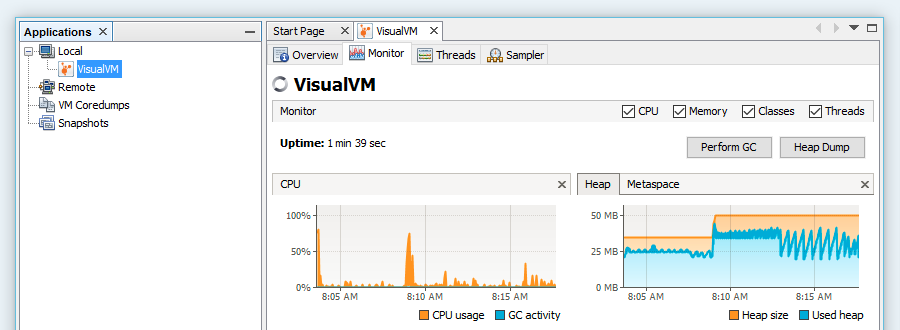
Java向けのプロファイリングツールの代表的なプロダクトとしてはVisualVMがあります。
- プロセスのパフォーマンスとメモリ状況の表示
- スレッドの状況を視覚化
- メソッド毎の処理時間を計測
などを行うことができます。
VisualVM 以外にも 高機能なプロファイリングツールとしてJava Flight RecorderとJava Mission Controlが存在していましたが、最近まで有償でのみ利用可能で、実運用環境への導入にはそれなりのハードルがありました。
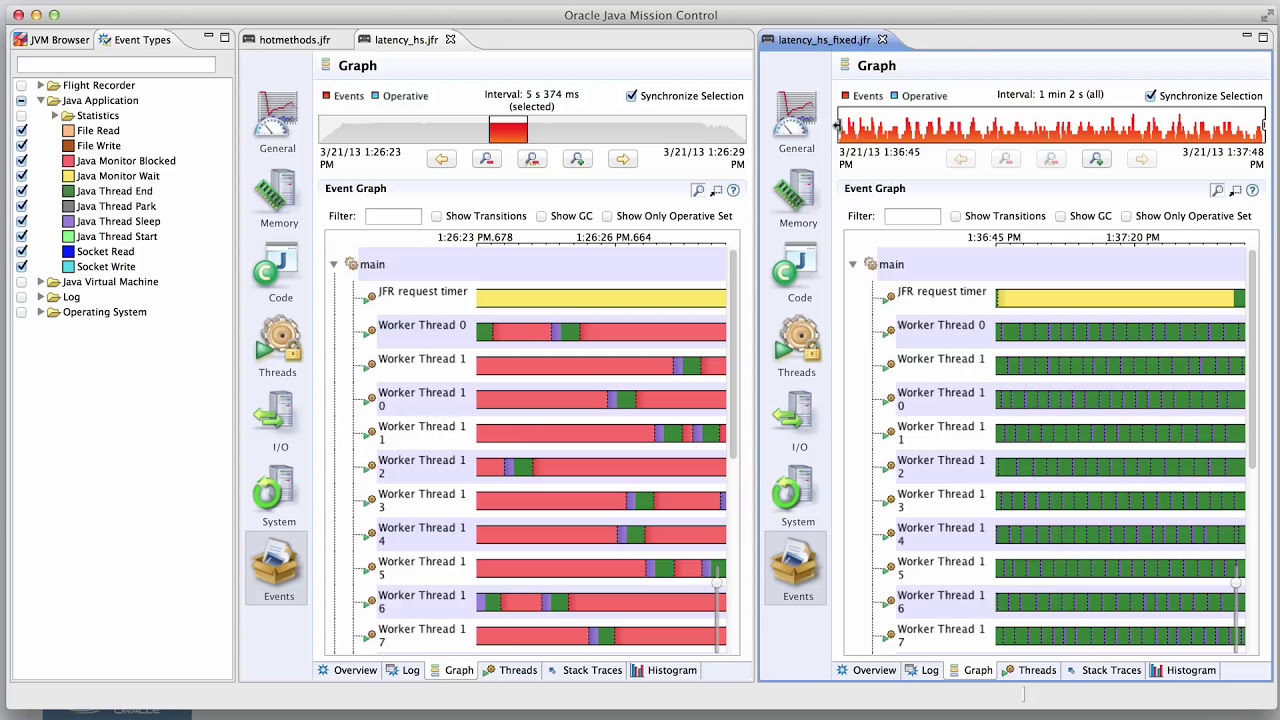
JDK8以降でOracle JDKのライセンスが変更となった時期に転機が訪れました。
JDK11以降でこの2つツールがオープンソース化され、プロダクション環境でも無償利用ができるようになったのです。この辺りの詳しい経緯や他記事に譲るとして、OSSとなった恩恵を受けられるようになったのは素晴らしいですね。
Java Flight Recorder とJava Mission Control で着目した点は以下の内容が計測できることです。
- ガベージコレクションによる停止時間
- コンテキストスイッチ回数
- 並行処理のブロッキングの発生箇所
また、VisualVMに比べて、Java Flight Recorder とJava Mission Controlの方が自動診断機能が使いやすかったり、計測できる内容も多かったので、今回はJava Flight RecorderとJava Mission Controlを利用することにしました。
並行処理とパフォーマンス改善の知識
並行処理はジョークで「人類には早すぎた」と言われています。 なんとなくでは行き詰まってしまい、メンテナンス性や拡張性が失われてしまうこともあるでしょう。
改めてパフォーマンス改善に関する情報、並行処理に関してキャッチアップして技法や注意点も参考にしました。
- Java並行処理プログラミング
- 並行処理の基本が書かれています
- https://www.sbcr.jp/product/4797337206/
- Effective Java
- パフォーマンスに関して度々言及があります
- https://www.maruzen-publishing.co.jp/item/?book_no=303054
- Javaパフォーマンス
- パフォーマンスに関する技法や基本から実践的な事まで書かれています
- https://www.oreilly.co.jp/books/9784873117188/
- Java SE APIリファレンス
- パフォーマンスに関するトレードオフやヒントも書かれています
- https://docs.oracle.com/javase/jp/13/docs/api/
また、分散処理の実務経験が豊富な方への相談・ディスカッションも重ねました。
戦略を立てる
リズムを作る
やったこととしてはまずはリズムを作る事です。 チューニング結果をローカル環境でシミュレーション計測できるようにしてから、実環境でも同様の結果となるか計測できるようにします。 取り組みの序盤で、簡単な変更によるチューニングを利用して、このサイクルがリズムよく回るようにします。
ローカル環境での計測
- 計測スクリプト
- ローカルファイルから検証用データを取り込み可能なように
ローカル検証を行う事で実装・実行・計測のサイクルが可能となり、実環境に投入するサイクルを早くできます。
実環境での計測
ほぼ本番データと同じデータ、トラフィック傾向(流量やバーストタイミング)も同じであることが望ましいです。 チーム内で環境を用意していただき、迅速にデプロイ・計測できるようにしました。
最新の成果を活用する
システムの保守という側面では、コストを減らすことを考えることが必要です。一つの手法としてはLTSサポートされているバージョンに固定しコード修正やテスト回数を減らすという戦略があります。私の観測範囲の中ではこの戦略が採用されている事が多いと感じています。
今回は、その真逆のアプローチをとります。 主要なライブラリやフレームワークは最新版を迅速に追従し続けるという戦略です。
この戦略はビックバンアップグレードによるアップデートが困難になる状況を防ぐことができ、動作保証さえできれば性能改善の成果や新しい機能を活かす事ができます。
また、JDKのLTSにこだわらない事で、利用バージョンをどんどんとあげていく意識的な内的動機の後押しもついてきます。
最新に保つことはメリットも多いのです。
初動の分担
チームでは二手に分かれました。
- サイクルを回すための整備
- コードを修正する前にJDKやフレームワークをバージョンアップ
最終的にバージョンアップをするのであれば、コードを書いてから出戻りがあるよりも最初にしてしまおうという事で、JDKやフレームワークの最新化を行いました。追加実装された機能もすぐに使えます。
JDKの最新版にしたら効果が出た
このバージョンアップ作業の開始と同時期にJDK13がリリースされました。 元々はJDK8で動作していたプログラムで、LTSのJDK11にあげることは既定路線で決まっていましたが、前述の戦略をステークホルダーに説明・合意を得て最新版のLTSではないJDK13にしました。
数年間のJVMの性能改善に期待して、実際に変更してみると... 効果が明確に数値として現れました!
メモリ使用量が半減したのです。 これには関係者皆が歓喜の声をあげたのは言うまでもありません。
ここで「良かったね」だけで終わってしまうのは、推測の域を脱しず今後も気になってしまいます。 そこでプロファイラを使って分析してみると、文字列のメモリ使用量が減っていたのです。
調べたところ JDK9で導入された JEP 254: Compact Strings の効果が大きかった事がわかりました。これは、「文字列データ内の文字の多くはASCIIなので、ASCII文字についてはchar(2バイト)ではなく、byte(1バイト)で取り扱うように変更しよう、その方がスペース効率あがるよね。」というものです。
Stringクラスを使う側は変更を意識せず利用でき、内部で切り分けくれています。
今回は扱うデータがほぼASCIIでしたので効果抜群だったというわけです。
そして、メモリ使用量に余裕ができたので、実装上、メモリ利用効率とトレードオフで検討できる方策の範囲も広がりました。
並行処理改善の着手
まずは並行処理改善の着手の前に、プロファイリング結果に沿ってコストが大きい処理を探し、プログラムの記述で無駄が発生しないようにゼロコピーとなるような実装に修正したり、データ構造を最適化したり、変換処理を中心に効率化を実施していきました。
地味な修正を経て
変換処理でコストがかかっていた例を一つ紹介します。 文字列からLocalDateTimeへの変換処理が特に遅いことがわかったので、DatetimeFormatterの処理実装を調査しました。 そうすると日付に対するパターンマッチで任意のマッチ項目が登場するごとにHashMapをコピーしていることがわかりました。
つまり、パターンマッチ走査回数を減らせば変換処理は速くなるということです。
DateTimeFormatter.ofPattern("YYYY[-][/]MM[-][/]DD")
このように4回走査が実行されていたものを
DateTimeFormatter.ofPattern("[yyyy/MM/dd][yyyy-MM-dd]")
とすることで走査は2回になります。
修正後のプロファイラ結果ではパース処理に掛かる時間が従来の1/3ぐらいに減りました。
並行処理をよりよい形に
並行で処理を行うことがこのシステムの中核でしたので、そこも大胆に効率的な処理になるよう改善を試みます。
着手前のコードの特徴としては同期的に並行に処理を行っていました。
プロファイラの計測結果から、同期的な処理となっているので他スレッドの処理完了を待つ待機スレッドが多く、スレッドを有効活用しきれていない事がわかりました。 つまり、スレッド数が同時に実行できる上限数という形となってしまい、最大パフォーマンスを出す為にコンテキストスイッチとのトレードオフの最適値を探り、大量のスレッドを使って性能を稼ぎ出すというアプローチを取らざるを得ない状況でした。
これではスレッド数が多くなればメモリ使用も徐々に増えていきます。
Redisとのやりとりを非同期化
そこで、スレッドを非同期化できそうな所を探し処理方式を変更していく事を検討しました。 非同期化にすることで少ないスレッドでリソースを使い切りたいという考えです。
JDK8から利用できるようになったCompletableFutureを利用をする事を候補として、まずは処理方式を比較するマイクロベンチマークを取ってみて、同期・非同期で性能がどれくらいでるか比べてみました。
簡単なコードを使ったマイクロベンチマークの結果は、同期処理では176スレッドが最大効率だったが、非同期処理では4スレッドで最大効率となりCPU使用率も同期処理に比べて少ない事がわかりました。
CompletableFutureを使って非同期化したら同期版と比べて約5.6倍速い結果となりました。
詳細な比較をしたマイクロベンチマーク調査については別記事でご紹介できればと思います。
こうして、実際プロダクトコードの処理書き換え前にマイクロベンチで測ると、作業価値の期待の見積もりができるという効果だけでなく、最適な選択をした結果で改善されたという理由づけにも繋がりました。
実際のプロダクトコードにも適用したところ、当初200スレッドところが14スレッドで同等のデータ処理を捌く事ができるようになり、使用メモリも50MBほど削減できました。また、若干ですが処理速度も向上しました。
気をつけたい事
今回はCompletableFutureを使って全体を非同期処理に書き換えましたが、チームでも慣れている人は少ないという状況でした。 また、CompletableFutureには扱う上で気をつけなければならないポイントがいくつかあります。たとえば処理ステップの途中に同期的な処理や時間の掛かる処理があった場合、著しい性能ダウンが発生してしまいます。
CompletableFutureに馴染んでもらうため、チーム内で勉強会を開催し設計コンセプトをしっかり理解しあって、プロファイラを使った計測の仕方やチェックすべきポイントを共有しました。
数値で見るコスト削減と成果
このように順序立てて計測・最適化・パフォーマンスチューニングを繰り返していって
- GCを極力発生させない
- 処理時間を短くする
- メモリ使用量を減らす
ことができ、結果的に利用しているクラウドリソースを大幅に削減し性能要件も満たす事ができました。
もう少し詳細に成果をお伝えすると、チューニング前はピーク時でメモリ使用量が最大20GB程度使用していたところが10GB程度となり、大幅に削減できました。
メモリ使用量がサーバーリソースの量に直結しており、メモリ使用量が少なくなったことで、クラウドの仮想マシンの台数も30%ほど削減することができました。
最後に
運用できることが最終ゴールです。
コンピュータリソースを減らした環境でもピーク時間帯でも処理遅延を防ぎ、CPUの頭打ちとOutOfMemoryを発生させず安定的に稼働させる必要があります。実環境で数日間の安定運用確認を経て、メトリクスの分析を重ね成果が確かなことがわかると、実感が湧いてきて歓喜の声がチームに響き渡りました!
地味な作業なのですが、システムを運用していくと、この様なチューニング作業は必要になる事が多いので、今後もこの知見を活かして違う機会に繋げていきたいと思います。