機械学習 社内勉強会レポート -野球Hackのためのデータ収集-
はじめに
昨今の機械学習ブームの盛り上がりを受けてか、弊社では、定期的に機械学習に興味のあるエンジニアが集まって勉強会を行っています。 現在、勉強会の取り組みの一つとして、MLBAMやSeanLahman、RETROSHEETで公開している野球データを使って、ピッチャーが次にどこに球を投げてくるのかという様な投球予測をしてみようということを行っています。そこで今回は、その取り組みについて、どういったデータを使おうとしているのか、また実際に機械学習をする前段としてどういった素性を扱うのか、といったことをお話したいと思います。
投球予測ができると何が嬉しいか
うまくいけば安定した老後生活を獲得できるからです!ということではないですが、試合観戦前に自分で入力した投球情報でシミュレーションなどできると、実際にシミュレーションが当たってそのシーンになった時に大盛り上がりできる!など楽しみ方は見出せるかと思います。
どんなデータがあると嬉しいか
突然ですが、野球の試合シーンを想像して、ピッチャーが次にどこに投げてくるのかという様な投球予測をしたいと思った時にどんなデータがあると嬉しいでしょうか。まず真っ先に候補に挙がるのは、いわゆる一球速報のようなものかと思います。ピッチャーがどこにどんな球を投げたのか、それが打たれたのかどうか、など投球や試合状況に関する詳細な情報があるとより良い予測ができそうですね。今回のメインとなるそういったデータ取得にうってつけなのが、Nakagawa Shinichiさんという方が作成してくださったpitchpxというPythonライブラリです(詳しくは、こちらを参考)。こちらを使って、MLBAMが公開しているデータを取得することができます(2007年~2015年分を取得しました)。また、投球ごとの情報は、レコードとしては以下の様な形になります。
final case class Pitch(
retro_game_id: String,
year: Int, // yyyy
month: Int, // MM
day: Int, // dd
st_fl: String,
regseason_fl: String, // レギュラーシーズンフラグ
playoff_fl: String, // プレーオフフラグ
game_type: String,
game_type_des: String,
local_game_time: String,
game_id: Int,
home_team_id: String,
away_team_id: String,
home_team_lg: String,
away_team_lg: String,
interleague_fl: String,
park_id: Int, // 球場ID
park_name: String, // 球場名
park_location: String, // 球場場所
inning_number: Int, // イニング
bat_home_id: Int,
outs_ct: Int, // アウトカウント数
pit_mlbid: Int, // ピッチャーのMLB ID
pit_first_name: String,
pit_last_name: String,
pit_box_name: String,
pit_hand_cd: String, // L or R
bat_mlbid: Int,
bat_first_name: String,
bat_last_name: String,
bat_box_name: String,
bat_hand_cd: String, // L or R
ab_number: Int,
start_bases: String, // ex) ___ , 1__ , _2_ , __3 , 123
end_bases: String, // ex) same as above
event_outs_ct: Int, // アウトカウント数
pa_ball_ct: Int,
pa_strike_ct: Int,
pitch_seq: String, // 投球判定履歴
pa_terminal_fl: String, // park terminal flag
pa_event_cd: Float, // park event code
pitch_res: String, // 投球判定
pitch_des: String, // 投球判定詳細 ex) strike out, swing out
pitch_id: Int,
x: Float, // 本塁からみたピッチャーの位置?
y: Float, // 本塁からみたピッチャーの位置?
// 1マイルは約1.6km/h
start_speed: Float, // リリース直後の球速 [マイル(mph)]
end_speed: Float, // 本塁に到達した時(ホームプレートの先端)に球速 [マイル(mph)]
sz_top: Float, // ストライクゾーンの上端 [feet]
sz_bot: Float, // ストライクゾーンの下端 [feet]
// PFX量は実際の投球の本塁上での位置と、投手が無回転で同じように投げた場合に想定される本塁上での球の位置の距離を表す指標である。
// スピン量が多い投手は数値が高くなる
pfx_x: Float, // PFX量の左右のブレ [inches]
pfx_z: Float, // PFX量の上下のブレ [inches]
px: Float, // 球が本塁に達した時の中央からの距離 [feet]
pz: Float, // 球が本塁に達した時の地上からの高さ [feet]
x0: Float, // リリースポイント [feet]
y0: Float, // 本塁からピッチャーまでの距離 [40,50,55] [feet]
z0: Float, // リリースポイント [feet]
vx0: Float, // リリース時の球速 [feet per second]
vy0: Float, // リリース時の球速 [feet per second]
vz0: Float, // リリース時の球速 [feet per second]
ax: Float, // リリース時の球の加速度 [feet per second per second]
ay: Float, // リリース時の球の加速度 [feet per second per second]
az: Float, // リリース時の球の加速度 [feet per second per second]
break_y: Float, // break lengthから本塁までの距離 [feet]
break_angle: Float, // 球が本塁に到達した点とリリースポイントとを結んだ直線、と、ピッチャーから本塁を結んだ直線、のなす角 [degree]
// BRK量は実際の球の軌道と、リリースポイントから本塁に達した時の球の位置を結んだ直線との距離の最大差を表す指標である。
break_length: Float, // BRK量につかう距離の最大最 [inches]
pitch_type: String, // 球種 ex) FF
pitch_type_seq: String, // 投球履歴 ex) FF|SL|FF|SL
type_confidence: Float, //
zone: Float, // ゾーン [1-9,12-14]
spin_dir: Float, // 回転方向 0 ~ 360 [degree]
spin_rate: Float, // 投げた直後の回転速度 [revolution per minute]
sv_id: String
)
なお、データの意味は以下のサイトなどを参考に調べました。
実際に予測を試してみる前に
さて、データが集まったところで、ひとまず取得したデータをそのまま素性として予測をしてみようか!と行きたいところですが、それでうまくいくかどうかは目的によって変わってくるかと思います。今回の投球予測の例ですと、バッター目線で考えて、ピッチャーが次に何を投げるのかというのはその投手の過去の球種配分(つまりは持ち球)などからも判断できそうです。そういった、時系列に関わるデータを素性として盛り込むことができると、より効果的な予測が出来そうですね。また、データの扱い方について、pitchpxで取得したデータの中に、ピッチャーがその打席で投げた球種の履歴(例:FF|SL|FF|SL、FFはフォーシームのストレート、SLはスライダー)というものがあるかと思いますが、これをそのままカテゴリ変数として扱うと変数のとる幅が多くなりそうなので1、2球前のものだけ見た方が良さそう、といったことも意識する必要があるかと思います(これで良いかどうかは、実際に予測を行ってトライ&エラーを繰り返しながら修正していくことになるかと思います)。そういったことを意識しつつ、ざっくりと予測に使えそうな素性を挙げると以下の様になりました。
- 投手に関する特徴量
- 投手の球種配分(連続変数)
- 例) ストレート:70%、カーブ:20%、スライダー:10%など
- 過去1年分の球種配分を次の1年分の素性として反映する
- 投手のコース配分(連続変数)
- これまでの配球
- 二球前・一球前の組み合わせ(カテゴリ変数)
- 投手の球種配分(連続変数)
- 打者に関する特徴量
- 打者の得意/不得意コース
- ゾーンを9分割して打率で表示(連続変数)
- 打者の得意/不得意コース
- 試合状況に関する特徴量
- ボール、ストライクのカウント(カテゴリ変数)
- アウトカウント(カテゴリ変数)
- ベース上のランナー(カテゴリ変数)
素性を見てみる
さて、どういった素性を扱うかを決めたところで、どういう意味合いを持ってくれそうか、実際に可視化して眺めてみたいと思います。Apache Zeppelinを使って、2015/08/07のデータを例に、素性として利用するデータを眺めると以下の様な形になりました。
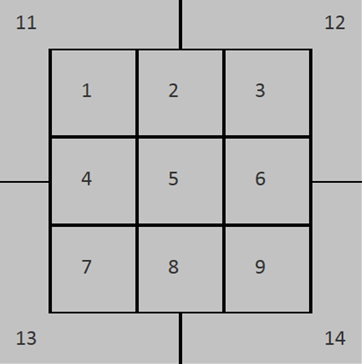
まず、上図のピッチャーの球種配分については、横軸が選手ID、色分けされた縦軸が球種配分を表しています。どの球種も満遍なく投げるということはなく、球種配分には偏りがある様に見える、つまり選手(あるいは選手をなにかしらの特性でグルーピングしたグループ)ごとに見分けられそうな癖があるという風に考えられます。次に、下図のピッチャーの投球ゾーンについてです。こちらにあるゾーンの定義に基づいて、1~9番のゾーンに絞って選手ごとのゾーン配分を求めました。こちらは、球種配分と見比べると、それほど偏りがない様にも見えます。実は、今回省いた11~14番のゾーンに投げられる球の方が多かったり、投球数が少ない選手も含まれていたりという影響もありそうなので、これでは有効活用できそうにないかもしれないという印象です。1年分のデータを使うとまた違った結果が得られるかもしれないので試す価値はあるかと思いますが(平均化されてさらに駄目になる可能性もありますが)、こういったことを事前に確認しておくと実際に予測を行ってみてからの考察がやりやすくなるかと思います。
{kind=link}
さいごに
今回は、野球の投球予測という例に関して、どういったデータを扱うかといったことを主に紹介しました。今回のように実際に予測を始める前にデータを眺めてみる、それがどういう作用を起こしてくれそうかを考えるというステップは大切だと思うので、より効果的な素性は何かを考えながら、次回以降の実際に予測をしてみるという部分に繋げていきたいと思います。
その他参考文献など
- SeanLahman
- 選手のセイバーメトリクスなどのマスタデータ
- 選手の強さごとにグルーピングやフィルタしたい場合に利用
- 野球関連指標解説
- 野球英語用語集
- pitch speed vs spin deflection angle
- PITCHf/x - Wikipedia
- Break versus Movement
{kind=link}